本文记录工作中一次异构数十亿级别数据库的过程,数据源为mysql,目标介质为elasticsearch。
1、 我们能利用的资源
1.1 源数据模型
源库是别人(库存)的数据,分为A,B,C三种类型的库存模型,需要将三种类型的模型整合成一中通用库存模型方便我方(商家)做业务。
典型的互联网企业是协作方式,通过数据副本实现业务之间的解耦。
1.2 特殊表(非重点)
D为库存占用订单详情,也要异构一份。
1.3 分库分表
ABCD均做了分库分表,A(16个库,4096张表),B(1,512),C(1,256),D(8,1024)
1.4 数据量
数据总量在数十亿级别
1.5 线上影响
不影响对方业务,数据源只有对方mysql分组中对应的抽数从库。
mysql分组解释
1.6 性能要求
未来要支持复杂的条件查询,对查性能有很高要求,目标介质是ES。
2、 难点
2.1 导数
交易库存复杂的分片规则,数据量大,导数是个大工程。
2.2 更新频繁
写操作频繁,ES 创建索引的tps能否满足要求。
2.3 一致性如何保证
通过mq 实现 base最终一致性。
3、 最终方案
3.1 系统整体架构
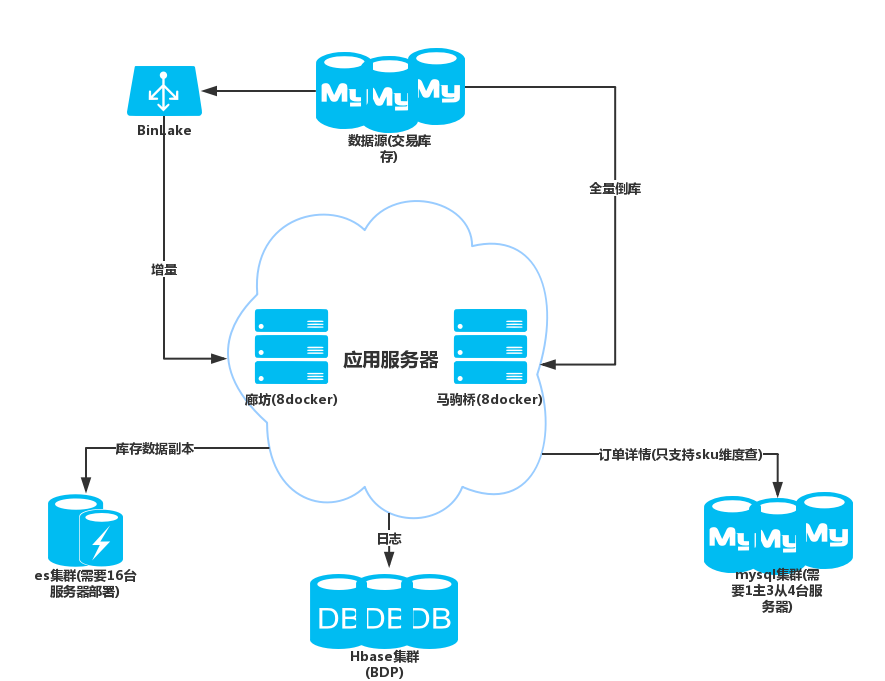
首先增量数据采用canal做收集(图中binLake同集群化canal),ABC库全部存入es,D库存入mysql。
3.2 如何做全量倒库
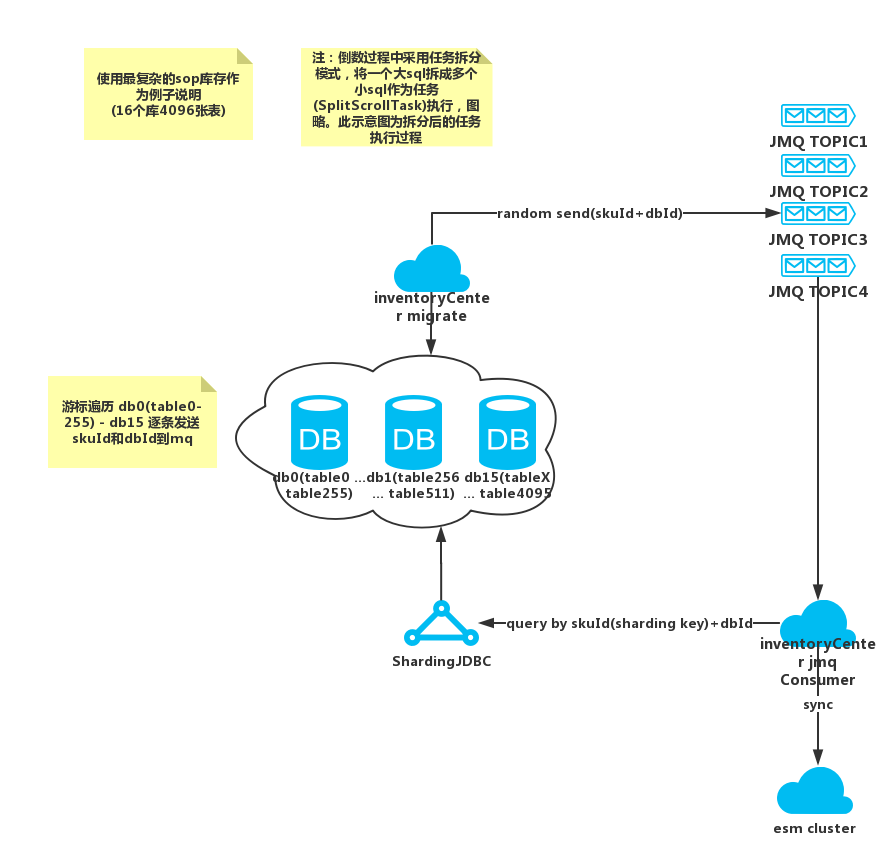
sop对应的类型A,使用多个topic分散消息中间件压力,同时解决中间件同一topic的连接数限制。
3.3 如何提高es写性能(bulk)
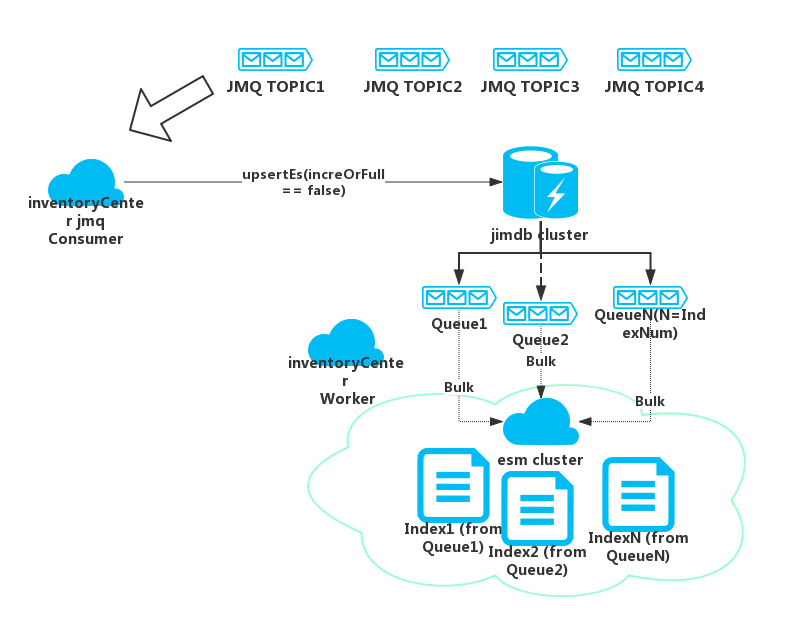
通过jmq异步创建es索引,通过redis队列实现bulk模式提交对应用的透明化